Lesson 3. Reinforcement Learning#
Reinforcement learning is a powerful tool with much success to aid decision-making under uncertainty in many complex domains. However, there is potential for biased or other disparate outcomes that must be considered and mitigated so as to avoid inequitable outcomes when applied to public health.
Health Equity and Reinforcement Learning
|
What is Reinforcement Learning?#
In reinforcement learning, an intelligent agent interacts with an environment to optimize sequences of decisions (policies) for long-term outcomes. The agent is aware of one thing, the goal of the experiment or model. This means the agent works through an environment with uncertainty and strives to maximize the total estimated future reward and minimize the penalties for poor actions. Observations from the environment and the reward function informs the agent, allowing it to learn from mistakes through trial and error and adjust its learned policies.
How Reinforcement Learning is Used#
Public health sectors often face decision making challenges while attempting to leverage a variety of data types and high dimensional spaces (or a large number of variables). Reinforcement learning can be utilized to leverage this data to enable better decision-making while managing uncertainty. A few examples of how reinforcement learning can be used are listed below:
Network Sampling: Reinforcement learning can be an approach to help identify populations for public health interventions.
Resource Allocation: Resource allocation is an essential aspect of public health interventions. A reinforcement learning model can help plan optimal allocations.
Evacuation Planning: Evacuation planning involves complex environments and variables. Deep reinforcement learning models can be utilized to develop plans that involve multi-exit evacuation [Xu et al., 2020].
Patient Health State: In healthcare, the environment is often a patient’s health state and the rewards relate to a patient’s health outcome. For example, a researcher may utilize reinforcement learning to examine the diabetic individual’s health state from EHR data to help determine what care steps should be taken. Data such as vital signs and laboratory test can be considered the historical data. The available treatments can be considered as actions. The patient’s improved or stabilized vital signs at discharge can be considered the reward [Gottesman et al., 2019]. Reinforcement learning models trained on EHR data have also been applied to the areas of HIV/AIDS, sepsis management, Parkinson’s disease, implanted cardiac device follow-up care and Heparin dosing [Smith et al., 2023].
Elements of Reinforcement Learning#
A Markov Decision Process (MDP) is the mathematical formulation for the reinforcement learning paradigm. It consists of multiple elements that forms a model that learns to map specific situations (states) to actions (policies) in order to optimize a specified outcome. The exact formulation of a reinforcement learning framework is very nuanced, specific to the research objective, and outside the scope of this lesson. However, descriptions are provided in the table below that include environment and model specific elements of reinforcement learning.
| Element | Description |
|---|---|
| Agent | An agent in reinforcement learning is the decision maker within the constructed environment. Through trial and error, an agent is able to perceive and interpret a situation then take actions. The environment either rewards or punishes these actions and this feedback allows the agent to learn. {cite:p}`li2018deep` |
| Environment | The constructed situation within the algorithm that the agent interacts with. The agent interacts with the environment by taking an action, causing a state transition, and receiving a reward {cite:p}`dong2020deep` |
| State Value Function | The value function is the expected total reward of each environmental state. It informs the agent of the value of being in a state s in the long run by taking into account possible next states and future rewards {cite:p}`li2018deep` |
| Reward Signal | For every action the agent takes, the environment sends it a reward signal based on the agent’s action and the current state. The sole goal for the agent is to learn from its actions to maximize the total reward {cite:p}`li2018deep` |
| Policy | The policy is a mapping of an agent's actions over all states in the environment {cite:p}`li2018deep`.
On-Policy: Estimates the return for state-action pairs assuming the current policy continues to be followed. This method estimates the value of the estimation policy while still using it for control. Off-Policy: Estimates the return for state-action pairs across all available actions. This separates a behavior policy (used to explore effects from different actions) from the estimation policy (used to update the actual learned policy) |
| Action Space |
The set of possible actions an agent can take Discrete: The agent selects a distinct action from a finite action setContinuous: The agent selects from actions that are expressed as single real-valued vectors |
| State Space |
The set of all possible environment states to which the agent can transition Discrete: State variable(s) only change at a discrete set of points in timeContinuous: State variable(s) change continuously over time |
| Operator |
Sets the method by which search is performed and state-action values estimated Sample-Means: Measures an average of state-action values state values over all sampled state-action observations during simulation. Off-line learning.Q-Values: Estimates the total expected reward over all state-action pairs, denoted as Q(s,a). On-line learning. |
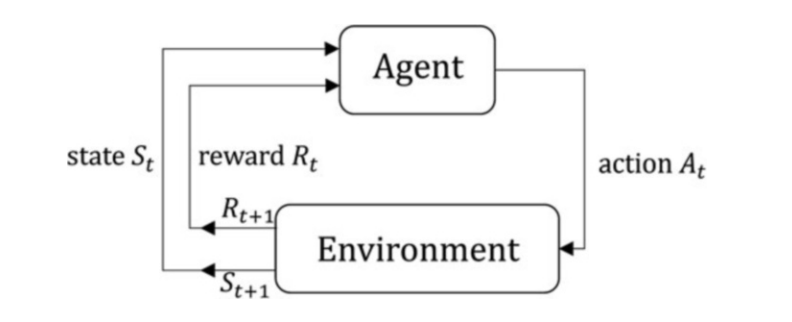
Figure 1: The high-level workflow above depicts the interactions of reinforcement learning elements
Reinforcement Learning Methods and Algorithms#
If you are already familiar with methods for reinforcement learning, please continue to the next section. Otherwise click here.
| Model | Common Usage | Suggested Usage | Suggested Scale | Interpretability | Common Concerns |
|---|---|---|---|---|---|
| Monte Carlo |
|
Method involves an agent learning by interacting with the environment and collecting samples | small - large | high |
|
| Q-learning |
|
|
medium | high |
|
| State–action–reward–state–action (SARSA) |
|
|
medium | high |
|
| Deep Q Network (DQN) |
|
|
medium-large | low |
|
| Deep Deterministic Policy Gradient (DDPG) |
|
|
medium-large | low |
|
Health Equity Considerations#
Reinforcement learning methods introduce many technical challenges needing attention from the practitioner. The table below highlights challenges and bias particular to reinforcement learning and their effects on health equity.
Challenge | Challenge Description | Health Equity Example | Recommended Best Practice | |
|---|---|---|---|---|
| Exploration vs Exploitation | The term "exploit" means to act greedily by taking the action that yields the maximum reward. To term "explore" means to act non-greedily by taking actions that don’t yield the maximum reward in order to learn more about them. Exploration vs Exploitation is the tradeoff between utilizing greedy policies or exploring new ones that may be more optimal. A balance must be achieved to encourage the agent to take risks on previously unselected actions while still learning from historical decision making and previous rewards and outcomes. | A study explored using reinforcement learning to encourage women to schedule mammograms by sending them a series of emails {cite:p}`bucher2022feasibility`. The methodology included using precision nudging which incorporates behavioral science and machine learning to overcome specific barriers to action. By looking at the number of people that opened emails, clicked on the links, scheduled mammograms, and completed mammograms, the system tuned how the emails were composed for different women taking into account demographics including income, education level, race, and age. The system was able to produce equitable results across these differences by adjusting the email messages over time, where each study participant received up to 40 emails during the two-year study period. This use of time and a variety of email messaging techniques demonstrates balancing exploration and exploitation. |
|
|
| Reward Structure and Delayed Rewards |
The agent is trained to maximize discounted future rewards instead of just the immediate rewards. Acting greedily for instant gratification may result in less optimal outcomes and lower expected rewards. In addition, designing the reward structure is often a highly subjective process and may incur bias. |
The reward structure for a reinforcement learning model influences behavior, which can inherit biases due to human or data influences. For example, reinforcement learning can be used to determine allocation decisions for a limited number of vaccines to affected populations. A biased allocation policy may be learned from a flawed reward structure which inadvertently influences disproportionately higher amounts of vaccines to be distributed among more wealthy areas, leading to waste of vaccinations in those areas, and also not providing enough vaccines in socioeconomically disadvataged areas. |
|
|
| Confounding Factors | Reinforcement learning estimates the quality of a decision based on historical data. However, historical data can be misinterpreted if there are confounding factors that are not represented in the data. |
|
|
|
| Multi-Agent Reinforcement Learning (MARL) |
Assess and learn the behavior for multiple agents each having individual motivations and pursuing their own targets in a shared environment. The complex group dynamics can incur the following challenges:
|
Emergency evacuation planning involves complex environments and variables and often require scaling for multi-exit evacuation strategies. Variables concerning the disaster and traffic conditions are often dynamic and may only have partial-observability. Lower income populations in urban areas tend to have higher population densities, so non-optimal outcomes related to multi-agent scalability and partial observability are likely accentuated for these communities in an emergency evacuation scenario. |
|
|
| Sim2Real |
Refers to the gap in transferability between the simulated reinforcement learning model to the real world scenario. If you view Q-learning as updating estimates in a two-dimensional array (Action Space * State Space), it, in fact, resembles dynamic programming. This indicates that the Q-learning agent will not have the ability to estimate values for unseen states. |
Emergency evacuation models may perform well within the confines of a simulation, but unforeseen obstacles may arise that the model has not seen before. This could cause the model to make catastrophic decisions at critical points in time {cite:p}`yang2022multiagent`. Studies of design practices identify inclusion and equity issues faced by those with varying degrees of divergency. Emergency evacuation routes typically consider mobility requirements (providing ramps, not only stairs), but may not account for cognitive diversity (elderly taking longer to process, neuro-diverse processing differences), color blindness, and sensory diversity (overwhelmed by so many people moving at the same time). These factors would be difficult to integrate into simulations, so would easily create sim2real differences that could slow down the evacuation and likely cause greater impacts for those affected. |
| |
| Scalability |
|
Network sampling may be applied to help identify regions that have populations requiring public health interventions. Performing this iterative sampling process can be time intensive, especially when using an algorithm that does not scale well to large data. Accommodating many potential equity concern factors easily exacerbates scalability issues, but removing these factors leaves the model more open to biased results. |
| |
| Historical data |
|
Groups are referred to as "underrepresented" because they are less likely to be considered, less likely to be included in initial studies, and less likely to be prioritized in policies and implementation. For this reason, normal reinforcement learning challenges related to historical data are accentuated for underrepresented populations. |
|
|
Case Study Example#
Case study is for illustrative purposes and does not represent a specific study from the literature.
Scenario: A researcher is optimizing a simulation around a flood disaster scenario to reopen public facilities after flood water contamination in an area.
Specific Model Objective: Train an RL model in order to learn a policy (a set of actions) that leads to safe reopening of public facilities (i.e., schools, playgrounds) while minimizing time to reopen.
Data Source: Data is sourced from a new flood disaster simulation system which simulates flood water contamination and provides environmental feedback to the RL agent that include realistic proxies for soil quality testing, educational resources, and cleanup measures.
Analytic Method: Deep Q-Learning: Deep Q Network (DQN) and Q-Learning algorithm
Results: Using a reward structure that is informed by measures for 1) public safety and 2) elapsed time. Average rewards are computed every 100 simulations and tracked. When a steady-state is reached, the researcher deems the model has finished training. When testing the final RL model, the simulated results showed all facilities were reopened with 0 safety incidents in 3.2 days on average.
Health Equity Considerations:
In a human-supervised test, the RL model was deployed to produce a policy to enable reopening of public playgrounds in several areas. Upon completion, it was observed that playgrounds were reopened in an average of 3 days, which was consistent with test results. However several potential safety incidents were observed due to structural integrity issues on playgrounds all located within less affluent neighborhoods. After examination, there are several contributing factors:
The simulation environment data did not account for important historical data and confounding factors in different socioeconomic areas, such as age of public facilities and differences in existing public safety infrastructure like proximity to nearby hospitals and access to emergency services.
The observed disparities point to a biased value estimate (the value of the current action policy relative to future rewards). The lack of critical a priori socioeconomic data, pointed out above, helps contribute to this bias.
The biased value estimate may also be a symptom of an improper reward structure. In this case, metrics tracking fairness in the rate of facility reopening in different socioeconomic areas should be reflected in the reward calculation. In addition, more training may be necessary with specific efforts on tuning the hyperparameters responsible for controlling sensitivity of delayed/future rewards.
Similar to supervised learning, the researcher should also consider tradeoffs with different RL algorithms such as Temporal Difference (TD) Learning (higher bias) vs Monte Carlo simulations (higher variance) and reassess model performance in a deployed setting.
Lastly, the researcher should always consider the most recent advances in RL model paradigms, such as Double Deep Q Networks (DDQN) and “Actor-Critic”, which specifically helps mitigate the value estimate bias problem, which will remain a realistic health equity issue that requires mitigation.
Considerations for Project Planning
|