Section 3. Natural Language Processing#
In this lesson you will learn about common methods and tasks in Natural Language Processing (NLP), health equity challenges in NLP, mitigation strategies for bias, and a detailed case study.
Health Equity and Natural Language Processing
|
What is Natural Language Processing?#
Natural Language Processing (NLP) is a sub-field of artificial intelligence, located at the intersection of computer science, statistics, and linguistics. The main goal of NLP is to use computer algorithms to extract, interpret, and generate information from human language, in both written and spoken forms. NLP systems evolved using rule-based approaches, and while those approaches (such as regular expressions) are still widely used today, current NLP methodologies are heavily based on statistical and machine learning methods [Jurafsky and Martin, 2014].
Below are a list of some of the core research areas in NLP. More details regarding specific NLP algorithms that make up these research areas and how they connect to health equity are provided in the subsection NLP Tasks and Algorithms below.
If you are already familiar with NLP research methods, please continue to the next section. Otherwise click here.
| Area | Common Usage | Example |
|---|---|---|
| Text Pre-Processing |
|
 |
| Morphologic and Syntactic Analysis |
|
 |
| Information Extraction |
|
 |
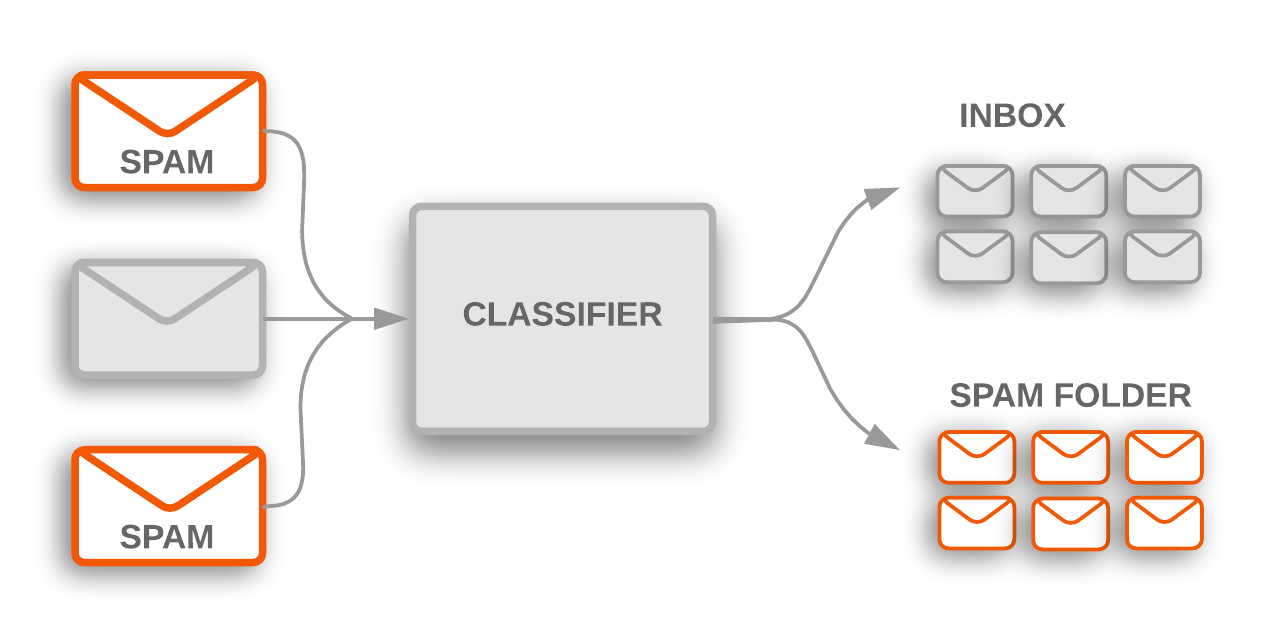
| Text Classification |
|
 |
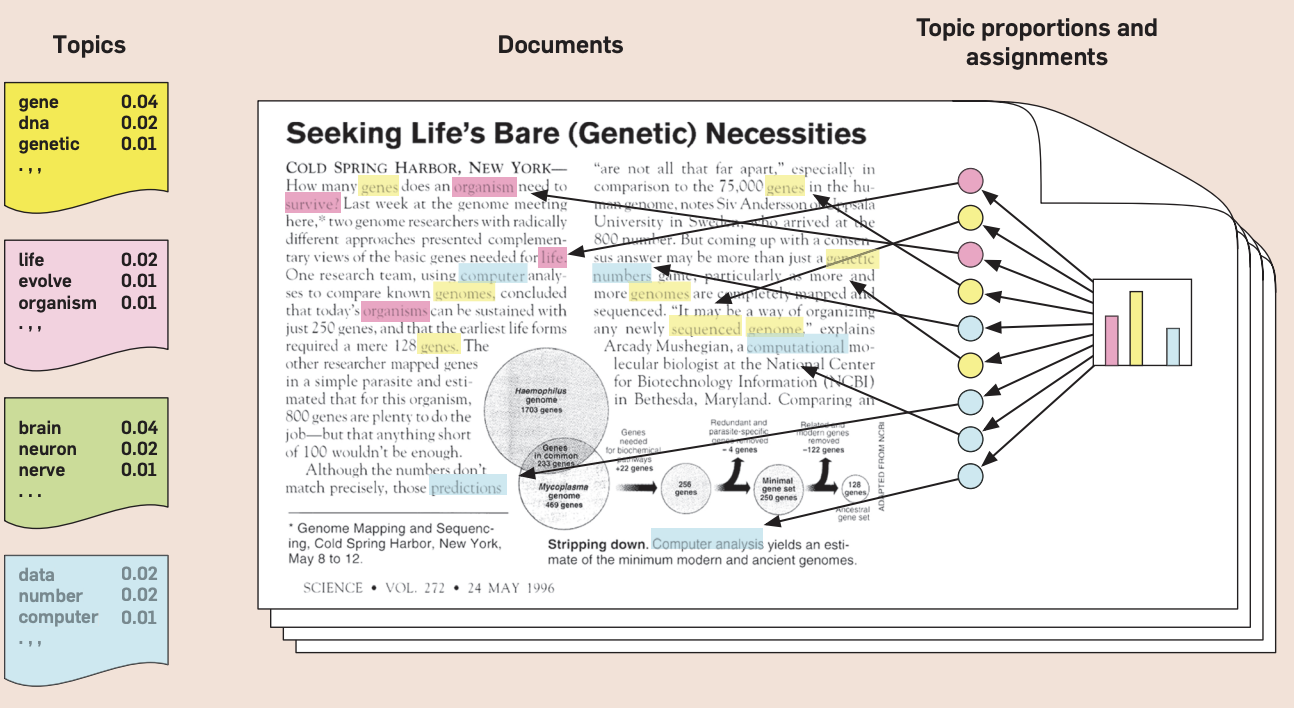
| Text Summarization |
|
 |
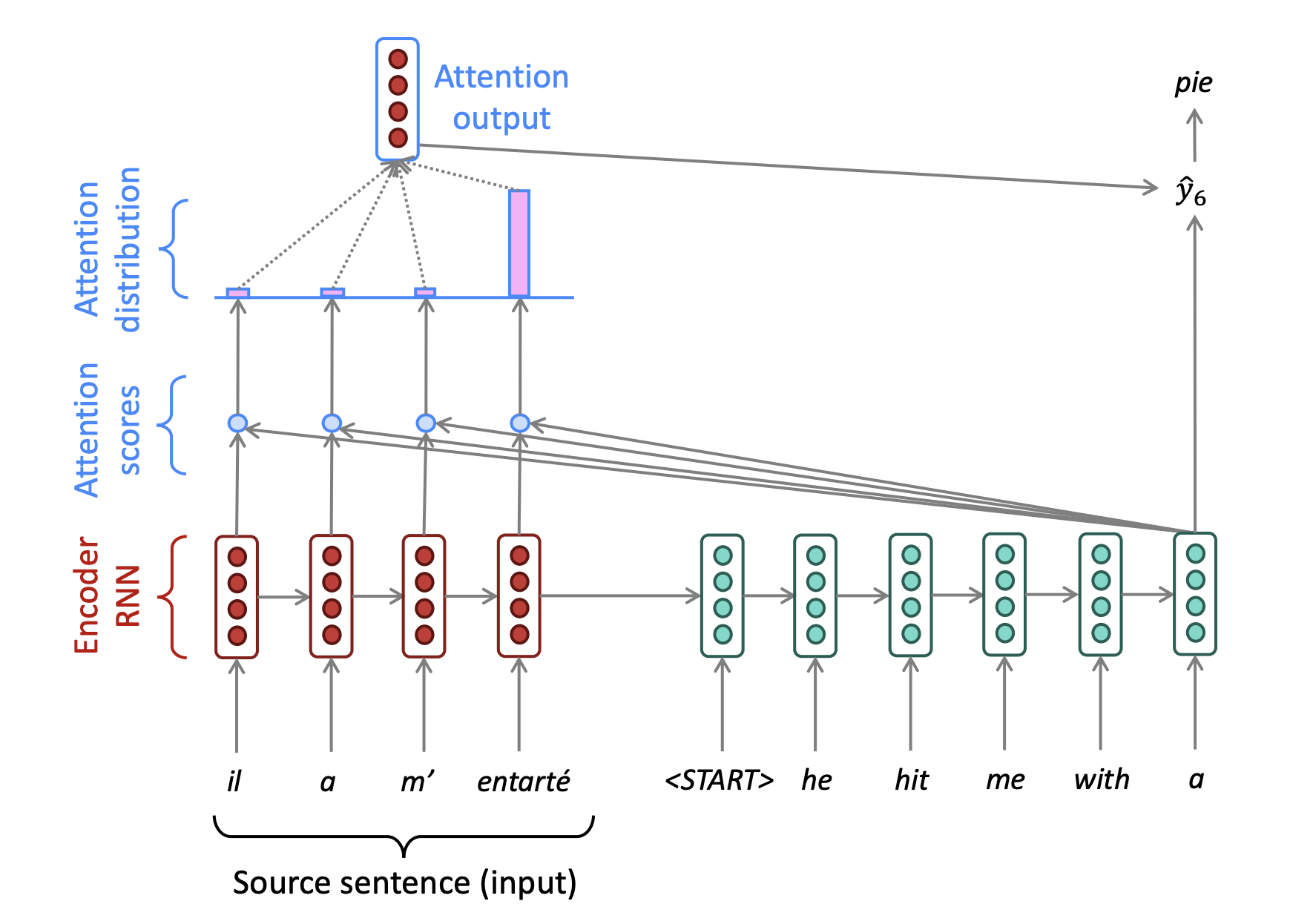
| Machine Translation |
|
 |
| Natural Language Generation |
|
 |
| Speech Recognition |
|
 |
[Text classification - Introduction, 2022, Blei, 2012, Dalianis, 2018, Ganesan, 2019, Gatt and Krahmer, 2018, Jurafsky and Martin, 2014, Manning, 2021, Nakayama et al., 2019, Patel and Arasanipalai, 2021, Prates et al., 2020]
How NLP is Used#
Some examples of NLP within the context of Public and Population Health are:
Public Health Surveillance using Social Media Researchers have used NLP on a variety of health conditions and behaviors, such as influenza, cancer, STIs, substance use, mental health, and others. An example study used Twitter to predict trends in alcohol consumption [Baclic et al., 2020, Conway et al., 2019, Curtis et al., 2018].
Accessing Key Information from Electronic Health Records (EHRs) There is a broad survey of observational health research using clinical notes from EHRs. NLP approaches may extend the information available for analysis, over just using structured data elements (medications, procedures, diagnoses, etc.). One example is extracting social determinants of health from clinical notes, which would not be traditionally documented elsewhere in the health record. These include things like social connectedness, housing, and food security [Baclic et al., 2020, Dorr et al., 2019].
Chat bots for communicating health information In wake of advances in improved chat bot capabilities, some public health agencies have used them to communicate health information, share resources, and coordinate distribution of supplies such as COVID-19 vaccinations and testing [Sam the chatbot, 2021].
Enhanced Literature Meta-Analyses NLP can be used to improve the accessibility of large bodies of health research with information extraction techniques to identifying topics and related articles. Additionally, NLP can be used to aid in the creation of meta-analyses by a semi-automated approach to article review [Baclic et al., 2020, Turner et al., 2005]
NLP Tasks and Algorithms#
Upon considering an NLP task or algorithm to use, it is good practice to consider the research goal, but also the source data. For example, if using an NLP model that was trained on social media data, it may not achieve the desired results on clinical notes. The following table highlights tasks and algorithms commonly used in NLP. Each task below details common concerns around bias and fairness, which will be discussed in greater detail in an upcoming section. More experienced readers who are already familiar with NLP may want to jump to the next sections regarding health equity.
If you are already familiar with NLP tasks and algorithms, please continue to the next section. Otherwise click here.
| Task / Algorithm | Common Usage | Suggested Usage | Suggested Scale | Interpretability | Common Concerns |
|---|---|---|---|---|---|
| Named Entity Recognition | Information Extraction |
|
Small to large text segments | Moderate |
|
| Language Modeling | Information Extraction, Text Summarization, Dialogue Systems, Machine Translation, Natural Language Generation |
|
Small to large text segments, depending on use case | Depends on Model |
|
| Word Embeddings | Information Extraction, Text Summarization |
|
Small to large text segments, depending on use case. Smaller text segments are used if comparing words, larger text segments may be used if comparing sentences or paragraphs. | Low |
|
| Part-of-Speech (POS) Tagging | Morphologic and Syntactic Analysis |
|
Generally smaller segments of text (e.g. sentences and paragraphs) | Depends on Model |
|
| Dependency Tree Parsing (DTP) | Morphologic and Syntactic Analysis |
|
Generally smaller segments of text (e.g. sentences and paragraphs) | Moderate |
|
| Co-reference Resolution | Information Extraction |
|
Generally smaller segments of text (e.g. sentences and paragraphs) | Depends on Model |
|
| Topic Modeling | Text Summarization |
|
Medium to large text segments | Moderate |
|
| Sentiment Analysis | Information Extraction |
|
Small to large text segments, depending on use case | Depends on Model |
|
| Natural Language Generation | * |
|
Generally smaller segments of text are generated, but varies. | Depends on model |
|
| Machine Translation | * |
|
Small to large text segments, depending on use case | Low |
|
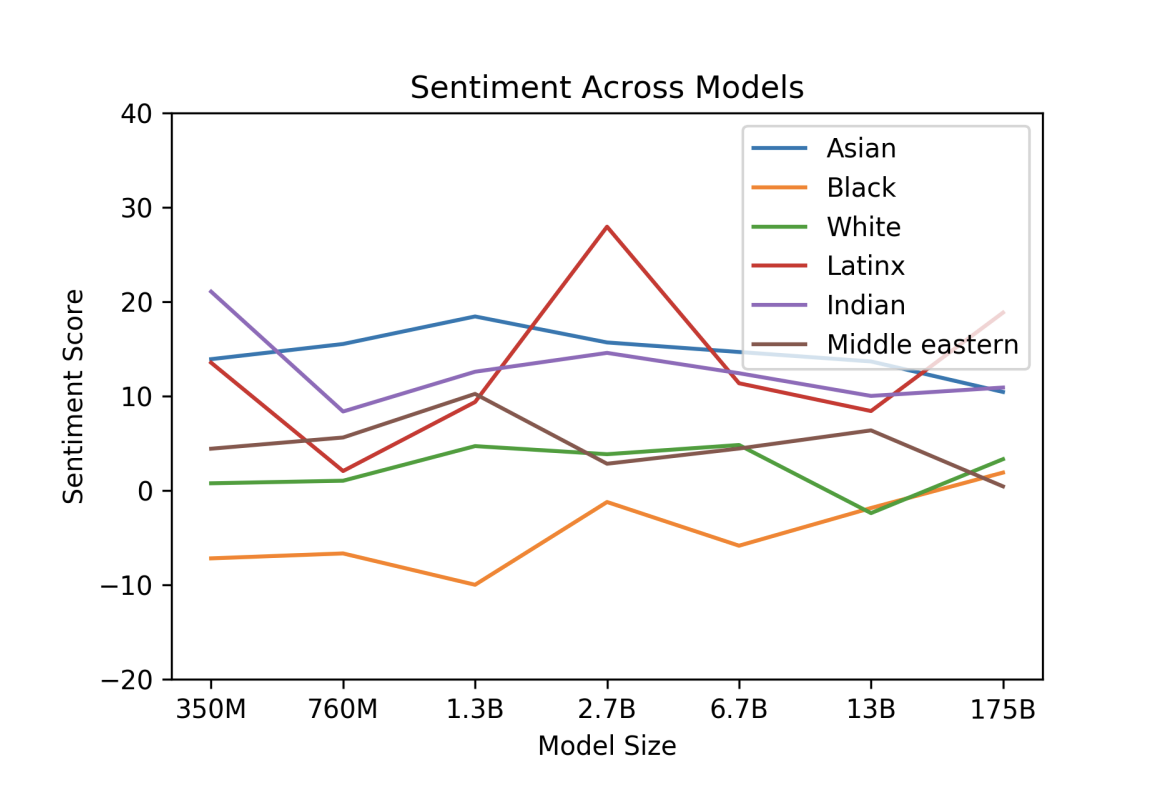
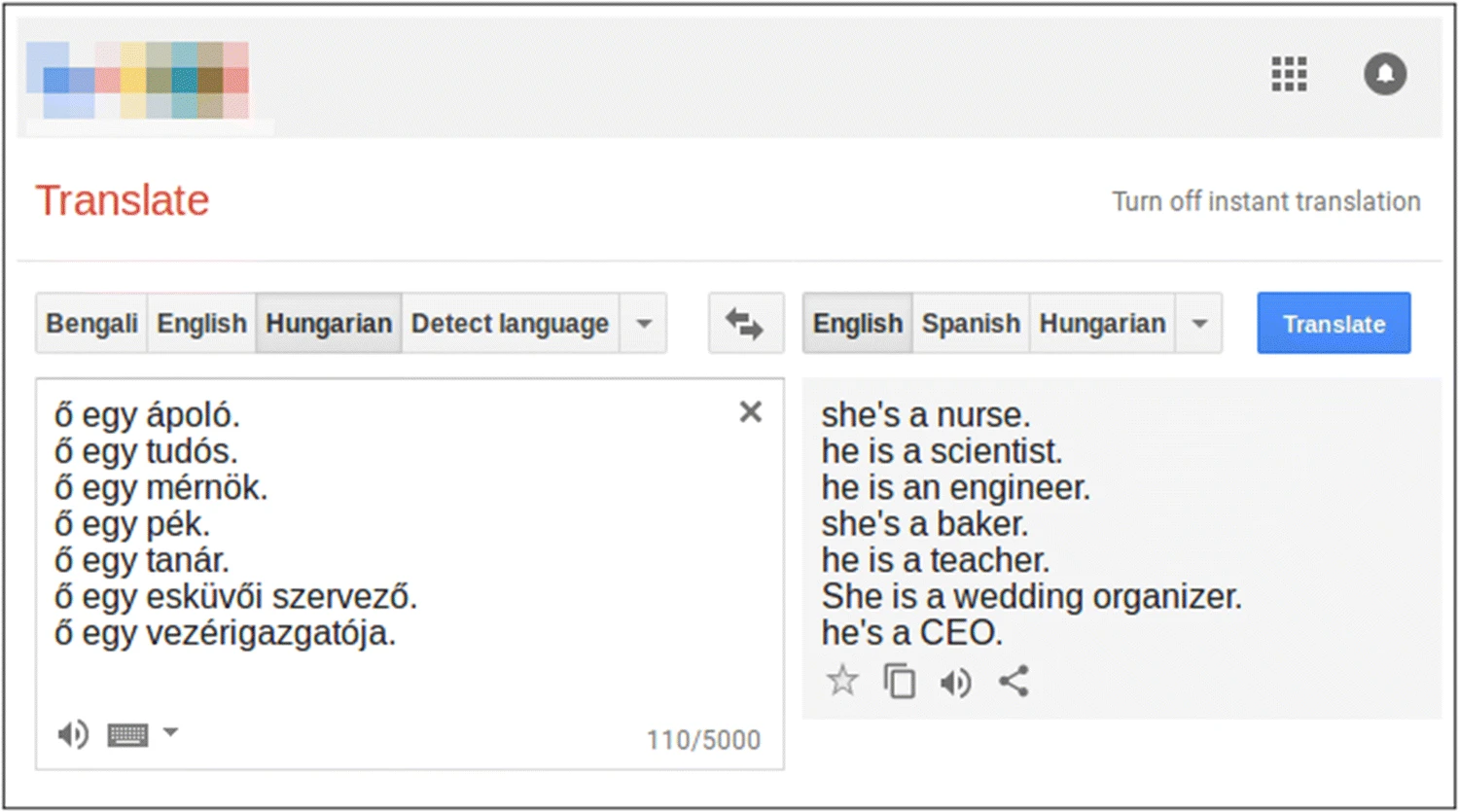
Mitigating Bias in NLP models#
Before introducing health equity considerations for NLP and challenges working with text data, we will introduce common ways to mitigate bias in NLP models and algorithms as they are often effective for different types of bias. While it is unlikely to be able to fully remove all bias in text, these techniques help mitigate many of the current biases that may be encountered:
Counter-factual Data Augmentation The process of enhancing and expanding the training set by replacing all male entities with female entities, and/or replacing with gender-neutral entities, e.g.
He was a biomedical engineer with an excellent reputation in his field.becomesShe was a biomedical engineer with an excellent reputation in her field.and/orThey were a biomedical engineer with an excellent reputation in their field.Re-sampling/Re-balancing The curation of training data by sampling techniques to ensure it is well-balanced, and representative. This means making sure speakers or authors of the text are as diverse as possible across multiple strata (including race, gender, socio-demographic status, etc.) and, in some cases, that the sample itself represents linguistic diversity, such as variety in tone, dialect, and language itself.
Audit and Evaluation Techniques In addition to de-biasing tasks during pre-processing and analysis steps, having audit and evaluation standards in place for NLP models (especially those using publicly trained models) is good practice. These include evaluation metrics for ensuring the model does not introduce known hateful language, biases, and prejudiced information from public sources such as social media platforms (e.g. Reddit, Twitter, etc.). Consider evaluation of the model on a dataset used to highlight specific types of bias, such as WinoBias.
[Caliskan, 2021, Dinan et al., 2019, Jurgens et al., 2017, Maudslay et al., 2019, Zhao et al., 2018, Zmigrod et al., 2019]
Health Equity Considerations#
Analysis with NLP may introduce many situations that are relevant to health equity. Below we highlight areas of consideration related to natural language processing. As with other analytics tools and models, the use and pervasiveness of NLP has outpaced the potential consequences of bias introduced from NLP models. One of the most common problems with NLP models is the introduction of demographic bias from real-world text data. This can include implicit biases and beliefs about race, gender, religion, sexual orientation, etc. to hate-speech, bullying, and stigmatizing language found on internet forums [Hovy and Prabhumoye, 2021].
Challenge |
Challenge Description |
Heath Equity Example |
Recommended Best Practice |
|---|---|---|---|
Bias from real-world data, including biases of gender, gender identity, race/ethnicity, sexual orientation, ability, and others |
NLP models trained on real world data can be susceptible to bringing in bias from real world examples and beliefs. For example, consider gender bias where (especially in the past), certain occupations, beliefs, descriptions, etc. were more likely to be associated with one specific gender. |
A researcher is studying the burnout of health workers from news articles and social media. Having a desire to capture demographic information, when no gender is mentioned, the researcher uses a model to infer it. This model however is biased as it always labels accounts that self-identify as nurses as being female. |
|
Annotator or Label Bias |
This comes from introducing bias from human annotators who may have explicit or implicit biases, are not familiar enough with the text, unable to understand the text or the research questions, or simply are not interested in providing good labels. This can be true especially in cases where labels are distributed out to the public. |
A researcher is investigating mentions of E.coli outbreaks in news articles. To train the model, they use a popular crowd-sourcing marketplace to generate labels. The research has a list of 500 articles to review. One eager annotator reviews over 350 of the articles and generates labels. Unfortunately, the annotator did not understand the research questions, and only labeled 5% of the articles correctly, leading to poor model performance and causing the researcher to start over from the beginning. |
|
Selection Bias (See more specifics on dialects below) |
The assumption that all language will map to standard English or a limited training data set, and the general failure to consider different linguistic, sociological, and psychological perspectives. Related to the availability heuristic, where models and tools are based on only the data that is available, which may inherently bias them. |
A researcher is seeking to understand how mental health conditions impact smoking behaviors. They craft a survey asking questions such as: “Describe a situation when you were depressed and turned to cigarettes.” and “Do you have a mental health condition that contributes to your smoking habits?”, etc. The researcher shares the survey with their colleagues and uses the responses to train a simple NLP model. However, when deploying it to several communities, including a primarily Korean community, a primarily Haitian community, and a community of mixed backgrounds, they are receiving very little feedback and seeing little success with their model performance. |
|
Bias in the use of publicly available models on English dialects and sociolects |
Pre-trained NLP models and word embeddings are trained on publicly available, standard-English corpora, such as Wikipedia and news articles. Depending on their source and original purpose, debiasing techniques may not have been performed or are not appropriate for your research question. Some examples include: when these models are used in more informal contexts (e.g. social media), they have difficulty detecting language correctly, and may also have difficulty with other NLP tasks. If used for other analytic tasks, they may introduce bias as they fail to map to non-standard dialects and/or non-native speakers. Other issues include racial and gender biases as described in previous examples. |
A researcher wishes to collect a selection of alcohol use discussions from Twitter, they use an English-based model to find only English speakers. However, after some review, the researcher finds that many tweets are being missed by the model because the model does not successfully identify tweets in African-American English and thus biases the research outcome. |
|
[Blodgett and O'Connor, 2017, Bolukbasi et al., 2016, Hershcovich et al., 2022, Hovy and Prabhumoye, 2021, Hovy and Spruit, 2016, Kirmayer and others, 2001]
While NLP can be used as a powerful tool in analyzing text data, there are points of bias that need to be considered in order to ensure your analysis does not introduce inequity. NLP tools and algorithms are susceptible to many of the same biases as biostatistics and machine learning models, however NLP models have additional considerations due to the complexity and richness of the source data.
Case Study Example#
Case study is for illustrative purposes and does not represent a specific study from the literature.
Scenario: EM is a public health researcher studying the possible social outcomes (homelessness, divorce, etc.) of alcohol and substance abuse in clinical narratives.
Specific Model Objective: Build an NLP tool to identify social outcomes documented in clinical notes that are associated with abusing alcohol and/or other substances.
Data Source: EM used electronic health data from an academic health system partner in an East coast metro area, with a racially and socio-economically diverse patient population.
Analytic Method: EM selected a random sample of 500 patients who had a diagnosis of an alcohol or substance abuse disorder. Using regular expressions to extract the ‘SOCIAL HISTORY’ section of the notes, EM first generated a topic model to see if a common set of social outcomes were apparent in the data. After the initial exploration, EM used a manually curated list of terms, the curated topic model results, along with results from a pre-trained named entity recognition algorithm, to build a NLP model which can extract social outcomes related to alcohol abuse.
Results: The NLP model identified certain phrases that were most commonly expressed in the patients’ social history write-ups, and could be used to highlight these social outcomes as possible risk factors for alcohol and substance abuse.
Health Equity Considerations:
Consider the research question design itself – are the social outcomes of alcohol/substance abuse tied to other factors which may be independent of alcohol/substance abuse (e.g. employment status, education, housing) and could incorrectly bias a patient?
Further, there are applications where the NLP model may be used as a feature engineering tool to aid a prediction problem with a supervised learning method. It is possible that confounding variables that do not exist in the training data can alter downstream predictive performance and therefore patient outcomes.
For example, the initial topic model may identify alcohol/substance abuse as a risk factor for a homelessness outcome. However, it may be that the lack of social support is a greater risk factor for homelessness, however it was not identifiable or present in the training data.
Using the output from topic models in clinical text may highlight stigmatizing language (e.g. junkie, druggie, drunk, etc.).
Consider how the named entity recognition (NER) algorithm was trained. This pre-trained model may exhibit demographic bias such as higher misidentification for minority ethnic names. If the NER model was also used to de-identify the training set, then this could lead to problems with privacy and undue harm to marginalized subgroups.
Using a limited training data set will limit the diversity of inputs used to train the final algorithm. This may increase the risk for overfitting and reduce performance on unseen data. If the training data was from an imbalanced sample (e.g. more female/older/white), then once the model is applied to a different input population (e.g. more male/younger/black) then it is likely that key features would be missed.[Healy et al., 2022]
Considerations for Project Planning
|